
Paperwork battles the increasing stacks of paper
Paperless

Paperwork was developed to manage the paperless office – a dream as old as desktop PCs.
The idea behind Paperwork [1] harks back to the dream of the paperless office: You scan incoming correspondence, invoices, and loose sheets then run them through an optical character recognition (OCR) tool that converts the content into digital form. An application then merges the image data and text in a superimposed form and saves it as a PDF.
Certain pitfalls await, however: For sufficiently good OCR you need the highest quality scans or photographs possible of the text pages. A good scanner with at least 600dpi resolution is preferred, (although 300dpi will work in some cases), and the OCR software needs to be the best fit for the job at hand. When Paperwork launches, it first searches for Tesseract [2]. If the program cannot find this very powerful OCR engine, the program falls back to Cuneiform. In most cases, Tesseract will give better results.
Getting Started
On Arch Linux, you can install Paperwork easily from the AUR. On Ubuntu, you will not currently find Paperwork in the repositories, and there is no PPA. Your best chance is to read the installation manual [3].
Paperwork is essentially based on four components. To scan the documents, Paperwork draws on Sane. Character recognition is handled by Tesseract or Cuneiform. Whoosh [4] indexes the OCR-converted texts so they can be searched easily, and the tool automatically generates suggestions for keywords. Paperwork then merges the whole enchilada into a graphical interface developed with Gtk/Glade.
The preferred Tesseract OCR engine originally came from Hewlett-Packard. Google uses the open source library system, for example, to digitize books [5]. The software excels with its excellent recognition rate and high level of automation. The drawback: Tesseract exclusively processes uncompressed TIFF input files; you thus need to convert documents where necessary.
The Paperless Office
On launch, Paperwork comes up with a clearly designed interface comprising three sections. On the left, you see the current document; next to that are the existing, scanned, and edited pages; on the right is the current page in detail. Like the gscan2pdf PDF scanner [6], Paperwork retrieves documents directly from a connected scanner or loads existing images from the hard disk.
The software merges scanned images to form projects and then exports the projects as PDF files. By default, Paperwork stores the projects in the papers folder in subdirectories named after the current date (e.g., 20140605_1350_31/). It creates several files in these directories: paper.<number>.jpg contains the JPEG images of the scanned page, paper.<number>.words contains the text extracted by the OCR engine.
These files are not stored as plain text files, however, but in the form of special XML files in hOCR format [7] containing the position in the original document in addition to plain text. It is not easy to read these files in a text editor, but you can superimpose the extracted text precisely on the image file. DjVu document format [8], which was specially developed for scanned documents, is based on this design.
Paperwork also stores preview images of the scanned pages in the directory. You can identify them by their thumb name component. Files with labels in their names store manually assigned labels for the document; a file stored as extra.txt additionally contains the keywords you assign.
Paperwork supports multiple sources for loading documents: the application can drive a scanner directly; the program automatically tries to find the scanner via the Sane back end. Alternatively, Paperwork also supports USB-connected webcams, which is usually not a good solution given the typically low resolution and poor quality. On the other hand, Paperwork uses images that have been created in any way as a source, such as screenshots of PDFs. A lack of image quality means the OCR engine rarely delivers useful results in these cases.
Additionally, Paperwork lets you edit PDF files directly. You can load these by selecting Document | Import file(s). If necessary, Paperwork will import several PDFs in one fell swoop – but not recursively from subdirectories. Thus, you need to store the data to be imported in a single directory.
Setting Up OCR
Before you start scanning documents, you need to set up the program (Figure 1). The icon for Settings is fourth from the left in the toolbar. In addition to configuring the working directory, you also configure the scanner and define the language for text recognition. Paperwork stores the settings in the ~/.config/paperwork.conf file, and it writes the index for all scanned documents to ~/.local/share/paperwork/index/.
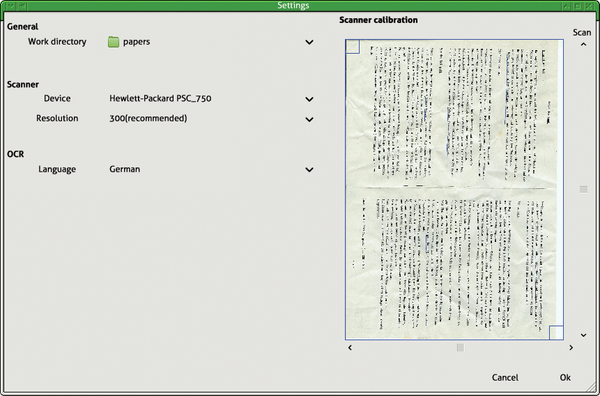 Figure 1: The Paperwork configuration is limited to a few settings.
Figure 1: The Paperwork configuration is limited to a few settings.
The scanner is calibrated in the settings dialog by clicking on the icon on the right. Paperwork then starts a scan, which it uses as the basis for further input to the device. How well this works depends to some extent on the fonts used.
Figure 2 shows an example in which the Paperwork OCR engine almost completely converted the text despite scanning at an angle. To see the words that were deciphered (in the blue frames), select Document | Advanced | Highlight all words. It is up to you to decide whether the plain text is accurate. In Figure 3, Paperwork tries its hand with a PDF generated by OpenOffice. This actually provides better conditions than a scanned document, but the result shows that many words were not recognized, as you can see from the number of words that lack blue boxes. Often, you can optimize the results by delimiting the area processed by the OCR engine in Document | Edit (Figure 4); however, this means a new, time-consuming OCR run each time you make a change.
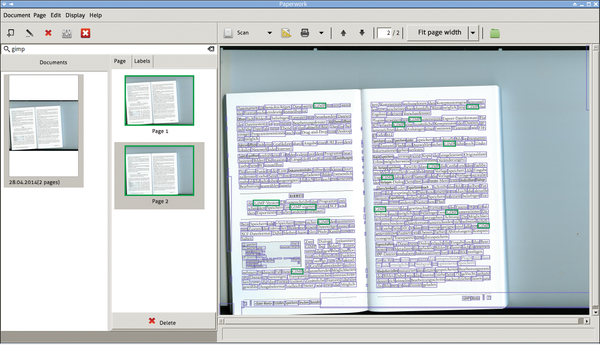 Figure 2: Paperwork's OCR achieved good hit rates, even with poorly aligned documents.
Figure 2: Paperwork's OCR achieved good hit rates, even with poorly aligned documents.
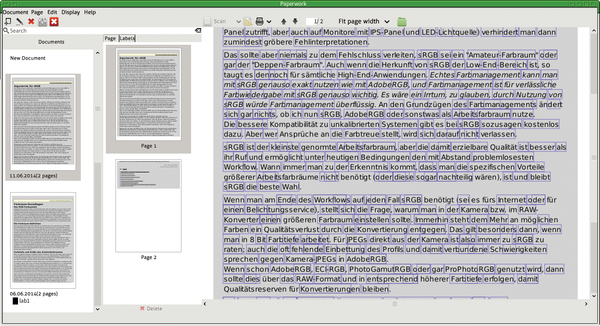 Figure 3: Text passages without blue boxes were not identified as text by the Paperwork OCR feature.
Figure 3: Text passages without blue boxes were not identified as text by the Paperwork OCR feature.
 Figure 4: You can narrow down the area to be processed in the image to optimize the OCR results.
Figure 4: You can narrow down the area to be processed in the image to optimize the OCR results.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
New Linux Kernel Patch Allows Forcing a CPU Mitigation
Even when CPU mitigations can consume precious CPU cycles, it might not be a bad idea to allow users to enable them, even if your machine isn't vulnerable.
-
Red Hat Enterprise Linux 9.5 Released
Notify your friends, loved ones, and colleagues that the latest version of RHEL is available with plenty of enhancements.
-
Linux Sees Massive Performance Increase from a Single Line of Code
With one line of code, Intel was able to increase the performance of the Linux kernel by 4,000 percent.
-
Fedora KDE Approved as an Official Spin
If you prefer the Plasma desktop environment and the Fedora distribution, you're in luck because there's now an official spin that is listed on the same level as the Fedora Workstation edition.
-
New Steam Client Ups the Ante for Linux
The latest release from Steam has some pretty cool tricks up its sleeve.
-
Gnome OS Transitioning Toward a General-Purpose Distro
If you're looking for the perfectly vanilla take on the Gnome desktop, Gnome OS might be for you.
-
Fedora 41 Released with New Features
If you're a Fedora fan or just looking for a Linux distribution to help you migrate from Windows, Fedora 41 might be just the ticket.
-
AlmaLinux OS Kitten 10 Gives Power Users a Sneak Preview
If you're looking to kick the tires of AlmaLinux's upstream version, the developers have a purrfect solution.
-
Gnome 47.1 Released with a Few Fixes
The latest release of the Gnome desktop is all about fixing a few nagging issues and not about bringing new features into the mix.
-
System76 Unveils an Ampere-Powered Thelio Desktop
If you're looking for a new desktop system for developing autonomous driving and software-defined vehicle solutions. System76 has you covered.