
Smart research using Elasticsearch
More, Please

Websites often offer readers links to articles about similar topics. Using Elasticsearch, the free search engine, is one way to find related documents instantly and automatically.
When people rummage around on the StackOverflow website looking for advice on programming questions, they can find list of links to related topics in the Related section (Figure 1). This helps users if the first search result didn't show what they expected or the located resource is insufficient. According to Gormley and Tong [1], Elasticsearch [2] [3], the free search engine, generates these links on the website in real time from the growing and very impressive collection of 10 million StackOverflow contributions.
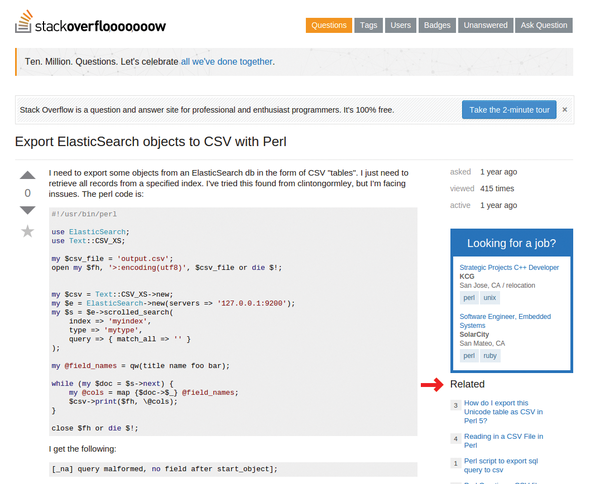 Figure 1: Using Elasticsearch, StackOverflow generates links to similar topics in the Related section.
Figure 1: Using Elasticsearch, StackOverflow generates links to similar topics in the Related section.
Artificial Brain
This isn't actual intelligence at work, because computers still find it difficult to understand the content of a document, meaning they can't find documents with related content. In fact, the algorithm used is based on simple nitpicking – it combines values for word frequency and derives a score from those values.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Nitrux 6.0 Now Ready to Rock Your World
The latest iteration of the Debian-based distribution includes all kinds of newness.
-
Linux Foundation Reports that Open Source Delivers Better ROI
In a report that may surprise no one in the Linux community, the Linux Foundation found that businesses are finding a 5X return on investment with open source software.
-
Keep Android Open
Google has announced that, soon, anyone looking to develop Android apps will have to first register centrally with Google.
-
Kernel 7.0 Now in Testing
Linus Torvalds has announced the first Release Candidate (RC) for the 7.x kernel is available for those who want to test it.
-
Introducing matrixOS, an Immutable Gentoo-Based Linux Distro
It was only a matter of time before a developer decided one of the most challenging Linux distributions needed to be immutable.
-
Chaos Comes to KDE in KaOS
KaOS devs are making a major change to the distribution, and it all comes down to one system.
-
New Linux Botnet Discovered
The SSHStalker botnet uses IRC C2 to control systems via legacy Linux kernel exploits.
-
The Next Linux Kernel Turns 7.0
Linus Torvalds has announced that after Linux kernel 6.19, we'll finally reach the 7.0 iteration stage.
-
Linux From Scratch Drops SysVinit Support
LFS will no longer support SysVinit.
-
LibreOffice 26.2 Now Available
With new features, improvements, and bug fixes, LibreOffice 26.2 delivers a modern, polished office suite without compromise.