
System monitoring for a new generation with Prometheus
Big Watcher

© Lead Image © Kurhan, 123RF.com
Legacy monitoring solutions are fine for small-to-medium-sized networks, but complex environments benefit from a different approach. Prometheus is an interesting alternative to classic tools like Nagios.
Where monitoring is required, alerting and trending are never far away. Alerting plays a major role in practically any monitoring environment; the idea is to draw the administrator's attention to failures. And, trending is also important. Trending helps the admin detect potential bottlenecks at an early stage.
A quick look at the available monitoring solutions shows why Monitoring, Alerting, and Trending (MAT) are still an issue for many networks, particularly large and complex networks. Nagios, which has dominated the monitoring market for a long time, is a behemoth of complexity and comes with some inherent weaknesses.
Nagios alternatives such as Icinga have attempted to address some of the issues, but their scalability is limited. The ballast of compatibility with Nagios and its plugins aggravates the situation. A state-of-art feature like trending was not exactly designed into the legacy Nagios. PNP4Nagios [1], a performance-tracking Nagios add-on, is one of the few options for useful trending with Nagios (Figure 1).
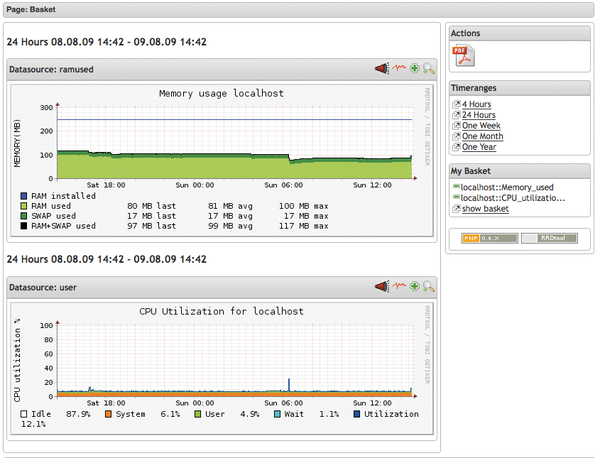 Figure 1: Legacy solutions such as PNP4Nagios generate heavy load when computing graphs and still take a huge amount of time – especially if you need to map longer periods of time.
Figure 1: Legacy solutions such as PNP4Nagios generate heavy load when computing graphs and still take a huge amount of time – especially if you need to map longer periods of time.
SoundCloud as the Precursor
SoundCloud from UK was confronted with the challenge of implementing a monitoring solution. The company operates a streaming service along the lines of Spotify or Apple Music. The real challenge from the outset was to build a MAT system that would work reliably with thousands of nodes. Instead of combining existing components to create a better-than-nothing solution, SoundCloud decided to explore unknown territory. The company chose to develop its own monitoring system and the result was Prometheus [2].
Compared with established solutions like Nagios, Prometheus has one very special feature: It comes with its own storage system to manage the data acquired from the network. Prometheus' internal database is based on the concept of the time series database. And, Prometheus tends to think more in the dimension of a complete metric rather than focusing on individual alerts. To understand what that means, I will take a short detour into the storage universe.
How MAT Systems Manage Data
Classic monitoring systems, such as Nagios, do not have very sophisticated data management, and they don't actually need it. The important thing with monitoring is whether a service is running properly right now. When you add the topic of trending, things start to become more difficult: Trending means you need long-term records relating to the availability of the service or the load on the existing infrastructure.
PNP4Nagios, for example, supports a database such as MySQL in the background in order to store the required values for a long period. MySQL is actually not designed for this kind of use, which can lead to problems. The volume of data you need to manage will grow extremely quickly in any large installation. The persistent storage on which all your trending data resides thus needs to scale just as easily as the entire platform. This is particularly true of the storage, but it also applies to the way in which the database handles a continuously increasing volume of data.
Also, preparing the data is a challenge: the data reaches the MAT system sorted in order of time, but at the other end, you'll need to output the data to reflect specific services. For example: the MAT system is regularly supplied with data points from its target systems for various services in consecutive order, such as "9AM: CPU load 1, RAM utilization 30 percent, and disc space usage 15 percent." However, administrators will typically want to know what the CPU load looked like in a specific period, for example between 9AM today and the same time the previous morning.
Storing and manipulating large amounts of data in a database is an extremely resource-hungry process, and MySQL, in particular, loves taking its time with queries from tools like PNP4Nagios. A time-series database, such as the database used with Prometheus, offers an alternative approach.
Basically, a time series database is no more than a database that is designed for storing data in temporal relation. (See the box titled "Not the First, But the Best.") The data is converted by algorithms directly in the database. Prometheus is thus better equipped to take on a complex task such as trending thanks to its data model.
Not the First, But the Best
Prometheus is not the first attempt to apply the time-series database model to network monitoring. Graphite [3] was around long before Prometheus, but its data model is not as mature. Influx DB [4], which is typically combined with a frontend such as Sensu, is even younger than Prometheus, but it addresses a different user group and, according to our tests, doesn't scale as well Prometheus when faced with large volumes of data. And, then there is OpenTSDB [5], the Open Time Series Database, which fundamentally is very similar to Prometheus but requires external add-on components such as Hadoop. The fact that these external constraints do not apply to Prometheus is something that many admins really appreciate about the product.
Typical monitoring and alerting is then no more than a side product: If no results are received for a specific metric over a period of time, the system assumes the service is not running correctly and sounds the alarm.
Prometheus Modular Architecture
Under the hood, Prometheus relies on a modular architecture. The core of the application – that is, the time series database – is programmed in Go, just like most of the applications in the Prometheus distribution. The database comes with its own web interface and a separate tool for alert management (the Alert Manager). Exporters for the target host are important – exporter is basically another word for agent: The node exporter, for example, logs various data for metrics such as CPU load or RAM usage on the host on which it is running, giving the Prometheus database the ability to pull this data when needed. If the service needs to push its data to the MAT system, you can deploy the push gateway, which fields the data from the services and stages it for the database.
At the heart of the system is the Prometheus server (Figure 2). The server handles many tasks, the most important of which is storing the measurement data acquired in the cloud. Although Prometheus comes from the cloud camp, the service is lagging behind in scalability. Although you can easily run any number of Prometheus instances within the same setup, in contrast to many other solutions, Prometheus does not rely on shared storage on the back end.
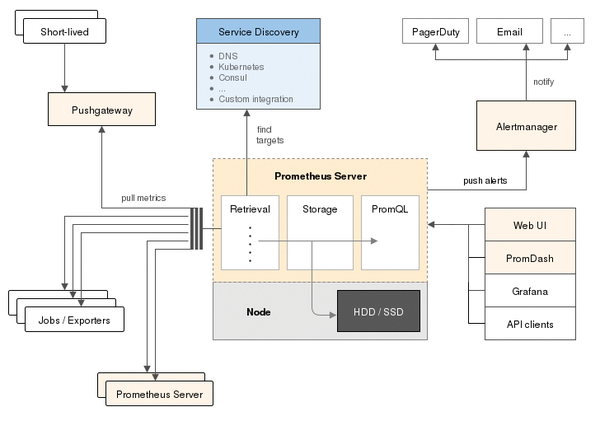 Figure 2: The hub of the Prometheus system is the Prometheus server, which communicates with all the other components.
Figure 2: The hub of the Prometheus system is the Prometheus server, which communicates with all the other components.
The Prometheus developers cite complexity as a reason for avoiding shared storage. They mention their competitor OpenTSDB as a negative example. Many admins would love to deploy OpenTSDB, but they are put off by the enormous overhead of running a complete Hadoop cluster.
Instead, Prometheus relies on the sharding principle. You can configure multiple instances of the Prometheus server service to cover overlapping data areas. Before performing a search, the database determines the shard in which the data in question must reside and it only looks there.
At this level, you can replicate by letting logical pairs of servers collect the data from the same agent on the network. A record is thus available multiple times and still usable in scenarios in which one of the two nodes has failed.
The Prometheus developers are aware that there is a problem with this lack of a shared storage alternative. Right now, they are working on a solution that generates a superordinate instance for a cluster of Prometheus installations; the instance, in turn, picks up the data from the Prometheus shards.
This approach gives users centralized administration. And there are plans for the distant future: In the long term, the intent is for Prometheus to store data in OpenTSDB – and thus leverage its replication capabilities.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Systemd Fixes Bug While Facing New Challenger in GNU Shepherd
The systemd developers have fixed a really nasty bug amid the release of the new GNU Shepherd init system.
-
AlmaLinux 10.0 Beta Released
The AlmaLinux OS Foundation has announced the availability of AlmaLinux 10.0 Beta ("Purple Lion") for all supported devices with significant changes.
-
Gnome 47.2 Now Available
Gnome 47.2 is now available for general use but don't expect much in the way of newness, as this is all about improvements and bug fixes.
-
Latest Cinnamon Desktop Releases with a Bold New Look
Just in time for the holidays, the developer of the Cinnamon desktop has shipped a new release to help spice up your eggnog with new features and a new look.
-
Armbian 24.11 Released with Expanded Hardware Support
If you've been waiting for Armbian to support OrangePi 5 Max and Radxa ROCK 5B+, the wait is over.
-
SUSE Renames Several Products for Better Name Recognition
SUSE has been a very powerful player in the European market, but it knows it must branch out to gain serious traction. Will a name change do the trick?
-
ESET Discovers New Linux Malware
WolfsBane is an all-in-one malware that has hit the Linux operating system and includes a dropper, a launcher, and a backdoor.
-
New Linux Kernel Patch Allows Forcing a CPU Mitigation
Even when CPU mitigations can consume precious CPU cycles, it might not be a bad idea to allow users to enable them, even if your machine isn't vulnerable.
-
Red Hat Enterprise Linux 9.5 Released
Notify your friends, loved ones, and colleagues that the latest version of RHEL is available with plenty of enhancements.
-
Linux Sees Massive Performance Increase from a Single Line of Code
With one line of code, Intel was able to increase the performance of the Linux kernel by 4,000 percent.