
How compilers work
Meticulous Transformer

Compilers translate source code into executable programs and libraries. Inside modern compiler suites, a multistage process analyzes the source code, points out errors, generates intermediate code and tables, rearranges a large amount of data, and adapts the code to the target processor.
Below the surface, a black box compiler handles complex processes that require good knowledge of machine theory and formal languages. Given the importance of compilers, it is not surprising that compiler construction is standard curriculum for computer science students. If you have never been to a college-level lecture on compiler theory – or if you went to the lecture but need a refresher course – this article summarizes the basics. (See the box titled "Teaching Material for Compiler Construction.")
In simple terms, a compiler goes through three steps: It parses the source code, analyzes it, and synthesizes the finished program (Figure 1).
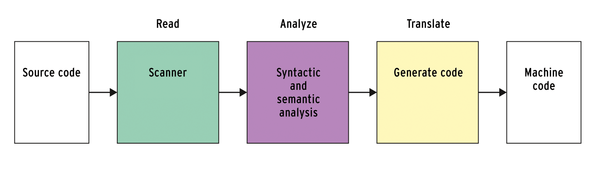 Figure 1: Rough structure of a compiler: parse code, analyze it, and create an executable program.
Figure 1: Rough structure of a compiler: parse code, analyze it, and create an executable program.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
Ubuntu Core 26 Offers Game-Changing Enterprise Features
Ubuntu Core 26 could be a game-changer for organizations looking for increased security and reliability.
-
AI Flooding the Linux Kernel Security Mailing List
AI is giving Linus Torvalds a headache, but not in the way you might think.
-
Top Priorities for Open Source Pros Seeking a New Job
Professional fulfillment tops the list, according to LPI report.
-
Container-Based Fedora Hummingbird Designed for Agent-First Builders
Fedora Hummingbird brings the same approach to the host OS as it does to containers to level up security.
-
Linux kernel Developers Considering a Kill Switch
With the rise of Linux vulnerabilities, the kernel developers are now considering adding a component that could help temporarily mitigate against them… in the form of a kill switch.
-
Fedora 44 Now Gaming Ready
The latest version of Fedora has been released with gaming support.
-
Manjaro 26.1 Preview Unveils New Features
The latest Manjaro 26.1 preview has been released with new desktop versions, a new kernel, and more.
-
Microsoft Issues Warning About Linux Vulnerability
The company behind Windows has released information about a flaw that affects millions of Linux systems.
-
Is AI Coming to Your Ubuntu Desktop?
According to the VP of Engineering at Canonical, AI could soon be added to the Ubuntu desktop distribution.
-
Framework Laptop 13 Pro Competes with the Best
Framework has released what might be considered the MacBook of Linux devices.