
How compilers work
Meticulous Transformer

Compilers translate source code into executable programs and libraries. Inside modern compiler suites, a multistage process analyzes the source code, points out errors, generates intermediate code and tables, rearranges a large amount of data, and adapts the code to the target processor.
Below the surface, a black box compiler handles complex processes that require good knowledge of machine theory and formal languages. Given the importance of compilers, it is not surprising that compiler construction is standard curriculum for computer science students. If you have never been to a college-level lecture on compiler theory – or if you went to the lecture but need a refresher course – this article summarizes the basics. (See the box titled "Teaching Material for Compiler Construction.")
In simple terms, a compiler goes through three steps: It parses the source code, analyzes it, and synthesizes the finished program (Figure 1).
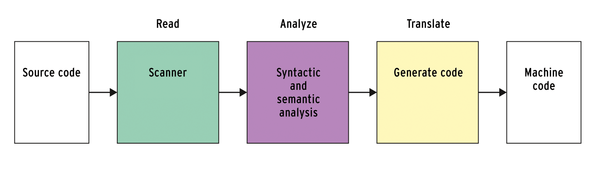 Figure 1: Rough structure of a compiler: parse code, analyze it, and create an executable program.
Figure 1: Rough structure of a compiler: parse code, analyze it, and create an executable program.
[...]
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
System76 Retools Thelio Desktop
The new Thelio Mira has landed with improved performance, repairability, and front-facing ports alongside a high-quality tempered glass facade.
-
Some Linux Distros Skirt Age Verification Laws
After California introduced an age verification law recently, open source operating system developers have had to get creative with how they deal with it.
-
UN Creates Open Source Portal
In a quest to strengthen open source collaboration, the United Nations Office of Information and Communications Technology has created a new portal.
-
Latest Linux Kernel RC Contains Changes Galore
Linux kernel 7.0-rc3 includes more changes than have been made in a single release in recent history.
-
Nitrux 6.0 Now Ready to Rock Your World
The latest iteration of the Debian-based distribution includes all kinds of newness.
-
Linux Foundation Reports that Open Source Delivers Better ROI
In a report that may surprise no one in the Linux community, the Linux Foundation found that businesses are finding a 5X return on investment with open source software.
-
Keep Android Open
Google has announced that, soon, anyone looking to develop Android apps will have to first register centrally with Google.
-
Kernel 7.0 Now in Testing
Linus Torvalds has announced the first Release Candidate (RC) for the 7.x kernel is available for those who want to test it.
-
Introducing matrixOS, an Immutable Gentoo-Based Linux Distro
It was only a matter of time before a developer decided one of the most challenging Linux distributions needed to be immutable.
-
Chaos Comes to KDE in KaOS
KaOS devs are making a major change to the distribution, and it all comes down to one system.