
Aggregating data with Portia
Itsy, Bitsy Spider

Are you interested in retrieving stock quotes in machine-readable form off the Internet? No problem: After a few mouse clicks, Portia weaves a command line and wraps the data in JSON format.
The Internet is a treasure trove of useful information, often residing on colorful HTML pages that are not easily extracted and processed. If you want to automate processing of current stock quotes or aggregate news, for example, you need to dismantle the HTML code of news portals such as CNN or Slashdot. This can be pretty ugly work.
Portia, a tool written in Python [1], promises a remedy; its name also refers to a genus of spiders, which would seem to make sense on the World Wide Web. The tool consists of a web application that, with a simple click, allows a user to select stock quotes, messages, and any other desired content. Portia then extracts this data and outputs it in JSON format.
Supported by a supplied web crawler, Portia can also ransack complete websites. As an example, if you need the headings from all Wikipedia articles, you show Portia exactly once where the headline resides on a Wikipedia page. The crawler then traverses the entire website and returns all matching headings in JSON format (see the "Warning" box for more information).
Warning
Data on third-party websites is typically copyright-protected. Developers should thus first obtain approval to add the information and text to their own projects.
Querying the data also generates a continuous load: The more subpages a website contains, the longer Portia will draw on the external web server. Its owner is likely to be anything but pleased about this and may turn to countermeasures in the worst case.
Spider's Web
Portia requires Python version 2.7, a C compiler, Git, the package with virtualenv, and the developer packages for libffi, libxml2, libxslt, libssl, and Python. On Ubuntu, the following command-line monster installs everything you need:
sudo apt-get install python-virtualenv python-dev \ libffi-dev libxml2-dev libxslt1-dev libssl-dev git
Users can now retrieve the source code from GitHub:
git clone https://github.com/scrapinghub/portia.git
Portia consists of several individual parts: Slyd provides the web application itself. Its partner in crime, Slybot, is a crawler, which loops through the selected web pages and harvests the desired information. To do so, Slybot draws on the services of Scrapy [2]. Slyd in turn delivers its pages via Twisted [3].
The commands in Listing 1 install all the components. The first line creates a virtual Python environment, and the second enables it. In this way, the Python components retroactively installed in the last line do not mix with those from your distribution.
Listing 1
Installing Required Python Components
If the installation completes without error, you can then launch Slyd:
twistd -n slyd
The command is spelled correctly – twistd is the Twisted daemon.
In the Vise
If you now go to http://localhost:9001/static/main.html in your browser, the page shown in Figure 1 appears. Portia currently only supports Chrome and Firefox; the developers recommend Chrome.
 Figure 1: The web application is quite clear-cut when first accessed.
Figure 1: The web application is quite clear-cut when first accessed.
Start by typing the URL of the page you want to tap in the search box at the top. After clicking on Start, Portia loads the page and displays it in the larger panel below. This may take a few seconds and may not work with some websites: For example, Portia refused to load the Linux Magazine site in our lab. If the desired page appears, Portia restricts your navigation options. On Wikipedia, for example, the web application disables the search function, but the links still work.
Next, you need to select the desired information. To do so, click on Annotate this page at the top. Portia now changes to selection mode: When you hover over an element on the page that can be cut out, Portia highlights it in blue. The HTML code appears in the black box at the top left.
The window shown in Figure 2 appears after clicking on the blue area. In the left drop-down list, you set the HTML attribute whose content you want to grab later on. For example, Content would provide the content of the HTML element; thus, you would choose Heading for the heading.
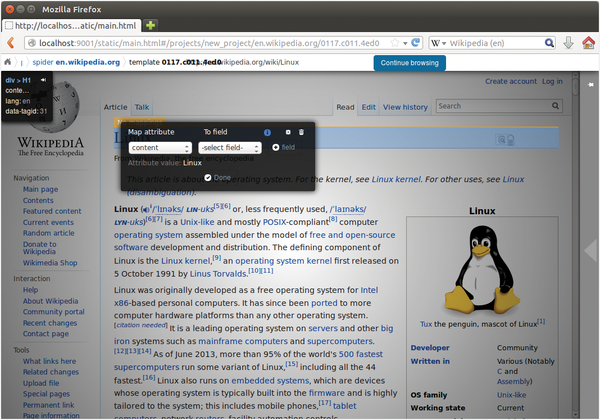 Figure 2: If you want to assign content to a field, you need a steady hand: Once the mouse leaves the black box, Portia immediately hides the box.
Figure 2: If you want to assign content to a field, you need a steady hand: Once the mouse leaves the black box, Portia immediately hides the box.
Scalpel
Next, select Create new below To Field. This opens another window, in which you can define the field's name and data type later on in the JSON data. The available options are the usual suspects: numbers and text, for example. Then, click on the green check mark to return to the previous screen. Follow the same steps to select all the other required data. Select Continue browsing to switch back to normal mode. Show items tells Portia to show you all the previously extracted data once again.
Starting with the currently loaded page, Slybot now follows all the links, cuts out the selected information, and delivers it back to you. As the master over the crawler, you can configure this behavior in the settings that are revealed by clicking on the gray triangle at the right edge of the page.
The Initialize slider lets you add more Internet sites to your project. To do this, simply type the URL in the empty box and then click the plus sign; a click on the URL opens the corresponding page in the main panel. When you get there, you can then select more areas to grab. If one of the sites uses password protection, just check the Perform login box and then type in the login data.
Buy this article as PDF
(incl. VAT)
Buy Linux Magazine
US / Canada
UK / Australia
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Subscribe to our ADMIN Newsletters
Support Our Work
Linux Magazine content is made possible with support from readers like you. Please consider contributing when you’ve found an article to be beneficial.

News
-
TUXEDO Computers Unveils Linux Laptop Featuring AMD Ryzen CPU
This latest release is the first laptop to include the new CPU from Ryzen and Linux preinstalled.
-
XZ Gets the All-Clear
The back door xz vulnerability has been officially reverted for Fedora 40 and versions 38 and 39 were never affected.
-
Canonical Collaborates with Qualcomm on New Venture
This new joint effort is geared toward bringing Ubuntu and Ubuntu Core to Qualcomm-powered devices.
-
Kodi 21.0 Open-Source Entertainment Hub Released
After a year of development, the award-winning Kodi cross-platform, media center software is now available with many new additions and improvements.
-
Linux Usage Increases in Two Key Areas
If market share is your thing, you'll be happy to know that Linux is on the rise in two areas that, if they keep climbing, could have serious meaning for Linux's future.
-
Vulnerability Discovered in xz Libraries
An urgent alert for Fedora 40 has been posted and users should pay attention.
-
Canonical Bumps LTS Support to 12 years
If you're worried that your Ubuntu LTS release won't be supported long enough to last, Canonical has a surprise for you in the form of 12 years of security coverage.
-
Fedora 40 Beta Released Soon
With the official release of Fedora 40 coming in April, it's almost time to download the beta and see what's new.
-
New Pentesting Distribution to Compete with Kali Linux
SnoopGod is now available for your testing needs
-
Juno Computers Launches Another Linux Laptop
If you're looking for a powerhouse laptop that runs Ubuntu, the Juno Computers Neptune 17 v6 should be on your radar.